UnityでサイトからHTMLソースを取得して
特定のタグの中身をcsv出力する機能が欲しかったので調べた。
UnityというよりはC#がメイン
①サイトにアクセスしHTML情報を取得
②タグごとに情報を取得
③CSV出力
①サイトにアクセスしHTML情報を取得
まずはUnityのリファレンスそのまま使ってみる。
HTTP サーバーからテキストやバイナリデータを取得 (GET)
https://docs.unity3d.com/ja/2018.1/Manual/UnityWebRequest-RetrievingTextBinaryData.html
unityの「www」でも同じことができる。
using System.Collections;
using System.Collections.Generic;
using UnityEngine;
using UnityEngine.Networking;//UnityWebRequestを使うために必要
public class htmlget : MonoBehaviour {
// Use this for initialization
void Start () {
StartCoroutine(GetText());
}
IEnumerator GetText() {
/*取得したいサイトURLを指定*/
UnityWebRequest www = UnityWebRequest.Get("https://sirohood.exp.jp/20190208-1792/");
yield return www.SendWebRequest();
if(www.isNetworkError || www.isHttpError) {
Debug.Log(www.error);
}
else {
// 結果をテキストとして表示します
Debug.Log(www.downloadHandler.text);
// または、結果をバイナリデータとして取得します
byte[] results = www.downloadHandler.data;
}
}
}
結果:取得できた。(ログに出力される)
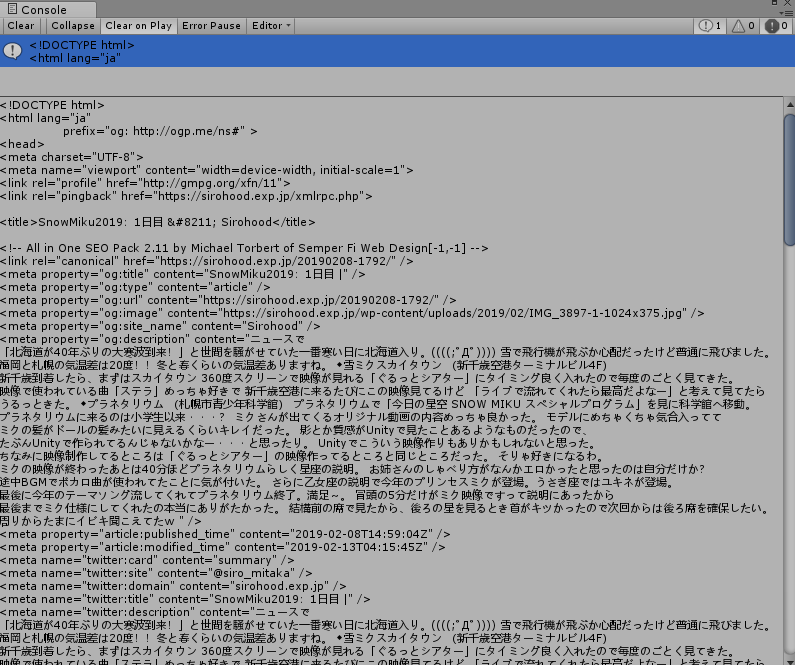
②タグごとに情報を取得
次に特定のタグの中身だけに絞る
正規表現を使って文字列を検索し、抽出する
参考:http://dobon.net/vb/dotnet/string/regexmatch.html#section4
「HTML内の<H>タグを抽出する」の箇所を組み込む
using System.Collections;
using System.Collections.Generic;
using UnityEngine;
using UnityEngine.Networking;//UnityWebRequestを使うために必要
public class htmlget : MonoBehaviour {
// Use this for initialization
void Start () {
StartCoroutine(GetText());
}
IEnumerator GetText() {
/*取得したいサイトURLを指定*/
UnityWebRequest www = UnityWebRequest.Get("https://sirohood.exp.jp/20190208-1792/");
yield return www.SendWebRequest();
if(www.isNetworkError || www.isHttpError) {
Debug.Log(www.error);
}
else {
// 結果をテキストとして表示します
//Debug.Log(www.downloadHandler.text);
// または、結果をバイナリデータとして取得します
byte[] results = www.downloadHandler.data;
//正規表現パターンとオプションを指定してRegexオブジェクトを作成
System.Text.RegularExpressions.Regex r =
new System.Text.RegularExpressions.Regex(
@"<(h[1-6])\b[^>]*>(.*?)</\1>",
System.Text.RegularExpressions.RegexOptions.IgnoreCase
| System.Text.RegularExpressions.RegexOptions.Singleline);
//TextBox1.Text内で正規表現と一致する対象をすべて検索
System.Text.RegularExpressions.MatchCollection mc = r.Matches(www.downloadHandler.text);
foreach (System.Text.RegularExpressions.Match m in mc){
//正規表現に一致したグループと位置を表示
Debug.Log("タグ:" + m.Groups[1].Value+
"\nタグ内の文字列:" + m.Groups[2].Value +
"\nタグの位置:" + m.Groups[1].Index);
}
}
}
}
結果:こんな感じにログが吐き出される
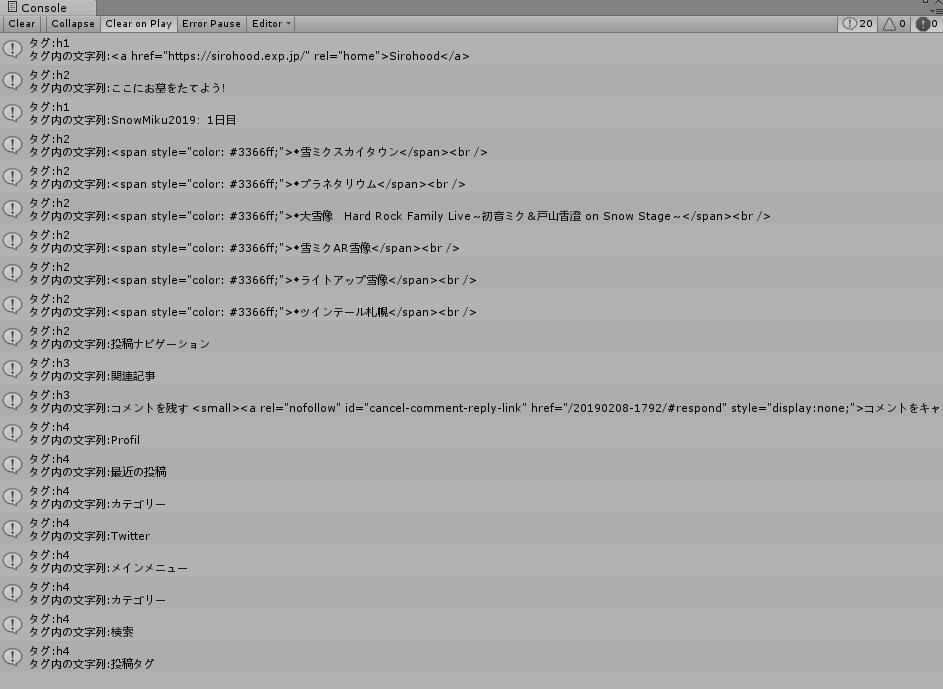
③CSV出力
[Unity] データを保存する(外部ファイルCSV)
参考:https://high-programmer.com/2017/12/10/unity-savedata-otherfile/
こちらも参考になりました。
using System.Collections;
using System.Collections.Generic;
using UnityEngine;
using UnityEngine.Networking;//UnityWebRequestを使うために必要
using System.Text;//Encodingを使うために必要
using System.IO;//StreamWriterを使うために必要
public class htmlget : MonoBehaviour {
// Use this for initialization
void Start () {
StartCoroutine(GetText());
}
IEnumerator GetText() {
/*取得したいサイトURLを指定*/
UnityWebRequest www = UnityWebRequest.Get("https://sirohood.exp.jp/20190208-1792/");
yield return www.SendWebRequest();
if(www.isNetworkError || www.isHttpError) {
Debug.Log(www.error);
}
else {
// 結果をテキストとして表示します。
//Debug.Log(www.downloadHandler.text);
// または、結果をバイナリデータとして取得します
byte[] results = www.downloadHandler.data;
//正規表現パターンとオプションを指定してRegexオブジェクトを作成
System.Text.RegularExpressions.Regex r =
new System.Text.RegularExpressions.Regex(
@"<(h[1-6])\b[^>]*>(.*?)</\1>",
System.Text.RegularExpressions.RegexOptions.IgnoreCase
| System.Text.RegularExpressions.RegexOptions.Singleline);
//TextBox1.Text内で正規表現と一致する対象をすべて検索
System.Text.RegularExpressions.MatchCollection mc = r.Matches(www.downloadHandler.text);
// ファイル書き出し
// 現在のフォルダにsaveData.csvを出力する(決まった場所に出力したい場合は絶対パスを指定してください)
// 引数説明:第1引数→ファイル出力先, 第2引数→ファイルに追記(true)or上書き(false), 第3引数→エンコード
StreamWriter sw = new StreamWriter(Application.dataPath + "/HTML_H.csv",true, Encoding.GetEncoding("Shift_JIS"));
// ヘッダー出力
string[] s1 = { "タグ", "タグ内文字","タグ位置" };
string s2 = string.Join(",", s1);
foreach (System.Text.RegularExpressions.Match m in mc){
//正規表現に一致したグループと位置を表示
/*Debug.Log("タグ:" + m.Groups[1].Value+
"\nタグ内の文字列:" + m.Groups[2].Value +
"\nタグの位置:" + m.Groups[1].Index);*/
// データ出力
string[] str = { m.Groups[1].Value, m.Groups[2].Value, m.Groups[1].Index.ToString() };
string str2 = string.Join(",", str);
sw.WriteLine(str2);
}
// StreamWriterを閉じる
sw.Close();
}
}
}
このスクリプトをオブジェクトにアタッチしてUnity実行すると
Assets内に「HTML_H.csv」というファイルができあがる。
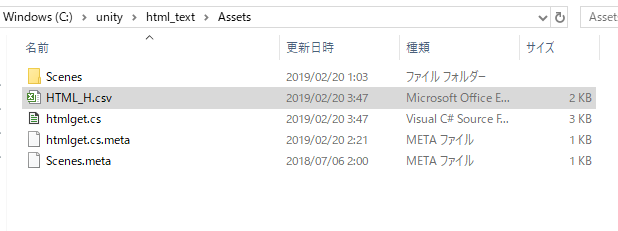
結果:中身はこんな感じ。

やりたかった事の基礎部分は完成。
◆特定タグから正規表現でデータを取得
ここからが本番。やりたかったこと。
正規表現の基本:http://dobon.net/vb/dotnet/string/regex.html
正規表現のオプション:https://docs.microsoft.com/ja-jp/dotnet/standard/base-types/regular-expression-options
指定のタグから値と属性を取得する:https://webbibouroku.com/Blog/Article/html-regex
正規表現を使って文字列を検索し、抽出する:http://dobon.net/vb/dotnet/string/regexmatch.html
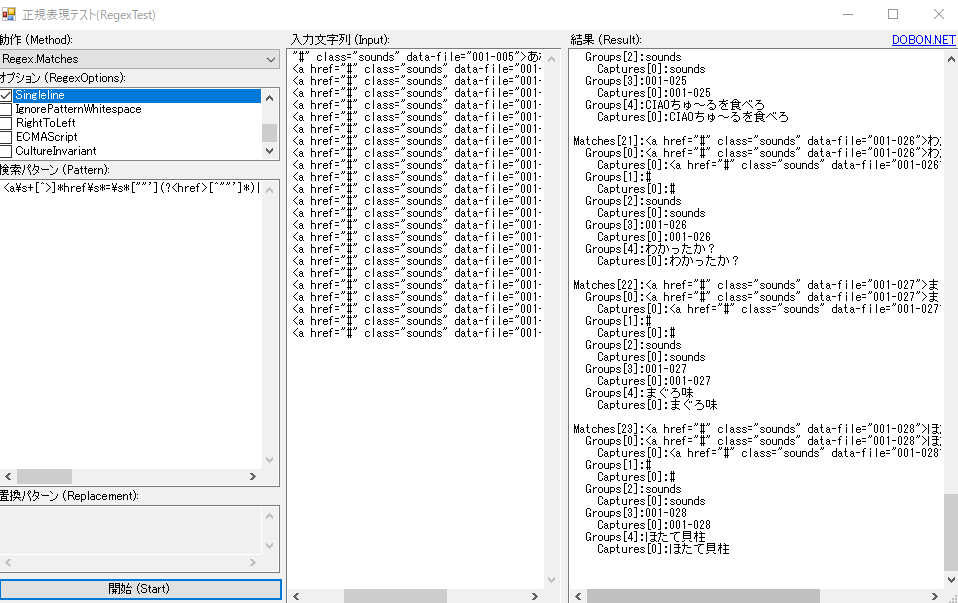
↑このサイト内「正規表現テストツール」めちゃくちゃお世話になりました。
正規表現テストツールの画面
例えば以下のHTMLソース
<a href="#" class="sounds" data-file="001-092">ぼくは完璧</a>
ここから
<a>タグのリンク先「#」
classの中身「sounds」
data-fileの中身「001-0092」
<a>タグの中身「ぼくは完璧」
が知りたい場合は以下のように書く
<a\s+[^>]*href\s*=\s*[""'](?<hrefGRP>[^""']*)[""']\s*class*=*[""']*(?<classGRP>sounds[^""']*)[""']\s*data-file*=*[""']*(?<datafileGRP>[^""']*)[""']*>(?<textGRP>[^<]*)</a>
(-д-;)何書いてるのか分からん
ワードパットで改行して色付けながら書くと分かりやすかった。
緑:HTML
太文字:グループ化
<a\s+[^>]*href\s*=\s*[““‘](?<hrefGRP>[^””‘]*)[““‘]
\s*class*=*[““‘]*(?<classGRP>sounds[^””‘]*)[““‘]
\s*data-file*=*[“”‘]*(?<datafileGRP>[^””‘]*)[““‘]*>
(?<textGRP>[^<]*)</a>
●取得結果
Matches[0]:<a href=”#” class=”sounds” data-file=”001-092″>ぼくは完璧</a>
Groups[0]:<a href=”#” class=”sounds” data-file=”001-092″>ぼくは完璧</a>
Groups[1]:#
Groups[2]:sounds
Groups[3]:001-092
Groups[4]:ぼくは完璧
↓意味
マッチ結果:
グループ0:一致した文
グループ1:<a>タグのリンク先
グループ2:classの中身
グループ3:data-fileの中身
グループ4:<a>タグの中身
C#の正規表現完全に理解した!\(´°v°)/
※してない
◆最後に
Unityでサイトから特定タグ情報出力は思ってた以上に簡単だった。
以前まとめたコレを組み合わせるといい感じのモノができるんですよ・・・。
今更ながらCSV形式よりもJSON形式で保存した方がいい・・?
※実際完全には理解できてないので表現がおかしいところや間違っているところがあれば指摘してください。
もう少し詳しく解説しながら
指定のタグ内から複数行を取得する方法をまとめました。
※コメントは承認後に表示されます。
コメントを公開されたくない場合、名前の後に「:非公開」とつけてください。